𝗛𝗶𝗴𝗵 𝗔𝘃𝗮𝗶𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗶𝘀 𝗴𝗲𝗲𝗻 𝘃𝗶𝗻𝗸𝗷𝗲
🔁 𝗛𝗶𝗴𝗵 𝗔𝘃𝗮𝗶𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆 𝗶𝘀 𝗴𝗲𝗲𝗻 𝘃𝗶𝗻𝗸𝗷𝗲
High Availability (HA) klinkt vaak als een vinkje in de pricing‑matrix, maar in de praktijk bepaalt het of jouw applicatie écht online blijft tijdens storingen, onderhoud en failovers.
🧩 𝗪𝗮𝘁 𝗯𝗲𝘁𝗲𝗸𝗲𝗻𝘁 𝗛𝗶𝗴𝗵 𝗔𝘃𝗮𝗶𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆?
Bij een High Availability‑database draait het om zo min mogelijk onderbreking van service, zelfs bij hardware‑ of softwarefouten. Redundante nodes vangen problemen op, terwijl failover‑mechanismen automatisch overschakelen naar een standby‑node als er iets misgaat. Cloudproviders benadrukken dit met termen als multi‑AZ, automatische failover en self‑healing clusters, maar zelden met concrete tijden voor hoe lang jouw database werkelijk onbeschikbaar is tijdens zo’n event.
☁️ 𝗗𝗕𝗮𝗮𝗦 𝗲𝗻 𝘀𝗰𝗵𝗶𝗷𝗻𝘇𝗲𝗸𝗲𝗿𝗵𝗲𝗶𝗱
DBaaS‑diensten van grote aanbieders beloven hoge beschikbaarheid: replicatie, automatische failover, onderhoud met minimale downtime en SLA’s van “drie tot vijf negens”. Toch zeggen die claims weinig over de echte outage‑tijd bij een geforceerde failover of een onderhoudsvenster, waardoor je in feite een black box koopt en niet weet welke impact een incident heeft op jouw workload.
⚠️ 𝗪𝗮𝗮𝗿𝗼𝗺 𝗷𝗲 𝘇𝗲𝗹𝗳 𝗺𝗼𝗲𝘁 𝗺𝗲𝘁𝗲𝗻
Voor serieuze productieomgevingen – zeker bij financiële, e‑commerce of SaaS‑applicaties – zijn antwoorden op die vragen bedrijfskritisch. Een outage van enkele minuten kan direct omzet kosten, en failover‑gedrag verschilt per provider, regio, instance‑type en engine. Daarom is het slimmer om niet alleen naar SLA’s te kijken, maar naar praktische metingen van HA‑gedrag: hoe lang ligt de boel écht plat bij een failover, en hoe snel herstelt throughput zich daarna.
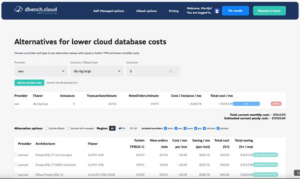
📊 𝗛𝗼𝗲 𝗗𝗕𝗲𝗻𝗰𝗵.𝗰𝗹𝗼𝘂𝗱 𝗵𝗲𝗹𝗽𝘁
DBench.cloud pakt precies die blind spot aan door cloud‑databases onder realistische omstandigheden te benchmarken. Er worden geforceerde failovers uitgevoerd (bijvoorbeeld handmatige switchovers of het killen van een node) en geplande failovers gemeten, zodat je weet wat een overschakelmoment je in de praktijk kost aan downtime. Op https://dbench.cloud/options/high-availability zie je deze metingen terug per provider, type, regio en engine, met echte tijden per scenario in plaats van alleen theoretische architecturen.
✅ 𝗧𝗲𝘀𝘁 𝗷𝗲 𝗛𝗔 𝘃𝗼𝗼𝗿 𝗷𝗲 𝗰𝗼𝗺𝗺𝗶𝘁
High Availability is meer dan een checkbox; het bepaalt of jouw business tijdens een incident blijft draaien of stilvalt. Door tools zoals
DBench.cloud en de HA‑overzichten op https://dbench.cloud/options/high-availability te gebruiken, kun je gericht kiezen welke DBaaS‑oplossing bij jouw risicoprofiel past – en ga je een migratie of nieuw project in met duidelijke verwachtingen in plaats van aannames.